Finding community structure in complex networks is an important first step to grasp inherent complex structure of social networks. Many research activities attempt to define the notion of communities and propose community analysis algorithms [2], [1].
We implemented a fast community analysis algorithm proposed by Clauset, Newman, and Moore [1] (CNM algorithm) and applied it to analyze various subsets of an acquaintance relationship network obtained from a social networking system (SNS). It performs well for a mid-scale subset of the network that consists of less than 500,000 users it was incapable to analyze larger networks.
We observed that merging in coupling pair of community structures, balancedness of the pair has great impact on computational efficiency of CNM algorithm. Based on this observation, we have implemented a slightly modified versions of CNM algorithm and observed remarkable speedup and slight improvement of the modularity.
Newman and Girvan attempt to measure the quality of network clustering by means of modularity [2]. Their algorithm (CNM algorithm) is a bottom-up agglomerative clustering which continuously finds and merges pairs of clusters trying to maximize modularity of the community structure in a greedy manner [1].
The authors have programed CNM algorithm and attempted to analyze an friendship network of an SNS called “mixi3 ” that hosted about one million users in October 2005. In spite of the good scalability as advertised in [1], we had to stop the experiment after a week when less than 10% of the whole analysis was finished.
To figure out the performance bottleneck, we conducted
community analysis on a various subsets of mixi SNS network. The
mixi SNS assigns each user an incrementa serial registration ID .
Let us represent the mixi SNS network by a graph
Gmixi= (U, F), where
U= { 1, 2, … } is the set of user IDs and
F⊂ U× Uis a set of friendship relationship. A subset of this graph
can be given as follows:
Gmixin= (Un,
F ∩ (Un × Un)) where
Un= {
u ∈ U | u≤n}
Figure 1 illustrates time required for analysis of various subsets: GmixiN. Each bar of the graph depicts time required to merge 10,000 community pairs. For most of the computation time is consumed for the first half of the merging process which decreases dramatically for the latter half.
[1] discusses the computational complexity of CNM algorithm can be approximated by O(n log2n), for nnodes but this approximation contracicts super quadratic cost illustrated in Figure 1.
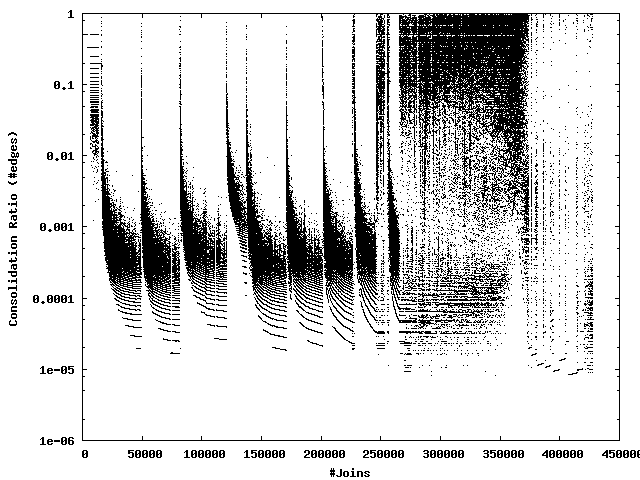
From the merge logs that record how community pairs are merged into larger ones, it was observed that only a few large communities are growing fast, merging in many tiny communities. Figure 2 presents unbalancedness of merge steps in the course of community analysis for Gmixi500K. For this purpose, we have defined the notion of consolidation ratio, which plots, for n-th merge step, ck:= join(ci, cj), (n, ratio(ci, cj)), where the size (s) of a community is measured in terms of the number of its links to other communities.ratio(ci, cj) ≡ min(s(ci) / s(cj), s(cj) / s(ci));Algorithm 1: Outline of the proposed algorithm.
while (true) {
updateDeltaQ();
Find (ci, cj) ∈ C2 that has maximum ΔQci, cjC⋅ratio(ci, cj).
if (max(ΔQci, cjC< 0) break ;
C := join(ci, cj);
}
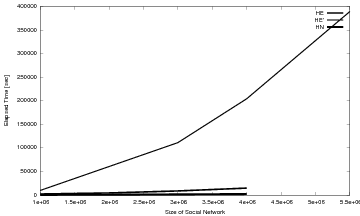
Table 1: Elapsed time (minutes):Java 5.0, 3.2GB Heap, Intel Xeon 2.80GHz.
| Gmixi200K | Gmixi400K | Gmixi600K | Gmixi800K | Gmixi1M | Gmixi4M | |
|---|---|---|---|---|---|---|
| CNM | 42.2 | 197 | NA | NA | NA | NA |
| HE | 2.15 | 6.80 | 13.6 | 24.5 | 36.2 | 243 |
| HE' | 8.52 | 35.5 | 68.2 | 124 | 173 | 3,400 |
| HN | 0.43 | 1.16 | 2.05 | 3.17 | 4.47 | 33.3 |
[1] A. Clauset, M. E. J. Newman, and C. Moore. Finding community structure in very large networks. Physical Review E, 70:066111, 2004.
[2] M. E. J. Newman and M. Girvan. Finding and evaluating community structure in networks. Physical Review E, 69:026113, 2004.
[3] Ken Wakita and Toshiyuki Tsurumi. Finding community structure in mega-scale social networks, February 2007, cs.CY/0702048.
*1 A long version of this paper is available online.
*2 This work is supported in part by the Grant-in Aid (No. 18300041) of MEXT, Japan.
*3 mixi is the largest invitation-based SNS in Japan and it hosts about 7 million users (Feb. 2007).