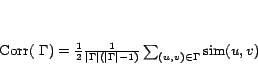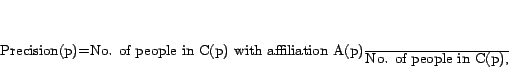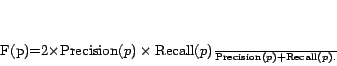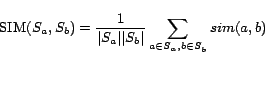3
H.3.3Information SystemsInformation Search and Retrieval Algorithms semantic similarity, Web mining
We propose an automatic method to measure semantic similarity between words
or entities using Web search engines.
Because of the vastly numerous documents and the high growth rate of the Web,
it is difficult to analyze each document separately and directly.
Web search engines provide an efficient interface to this vast information.
Page counts and snippets are two useful information sources
provided by most Web search engines. Page count of a query is the number of pages
that contain the query words 1. Page count for the query P AND Q
can be considered as a global measure of co-occurrence of words P and Q.
For example, the page count of the query ``apple'' AND ``computer'' in
Google 2 is ![]() , whereas the same for
``banana'' AND ``computer''
is only
, whereas the same for
``banana'' AND ``computer''
is only ![]() . The more than
. The more than ![]() times more numerous page counts for
``apple'' AND ``computer'' indicate that apple is more semantically similar to
computer than is banana.
times more numerous page counts for
``apple'' AND ``computer'' indicate that apple is more semantically similar to
computer than is banana.
Despite its simplicity, using page counts alone as a measure of co-occurrence of two words presents several drawbacks. First, page count analyses ignore the position of a word in a page. Therefore, even though two words appear in a page, they might not be related. Secondly, page count of a polysemous word (a word with multiple senses) might contain a combination of all its senses. For an example, page counts for apple contains page counts for apple as a fruit and apple as a company. Moreover, given the scale and noise in the Web, some words might occur arbitrarily, i.e. by random chance, on some pages. For those reasons, page counts alone are unreliable when measuring semantic similarity.
Snippets, a brief window of text extracted by a search engine around the query term in a document, provide useful information regarding the local context of the query term. Semantic similarity measures defined over snippets, have been used in query expansion [36], personal name disambiguation [4] and community mining [6]. Processing snippets is also efficient as it obviates the trouble of downloading web pages, which might be time consuming depending on the size of the pages. However, a widely acknowledged drawback of using snippets is that, because of the huge scale of the web and the large number of documents in the result set, only those snippets for the top-ranking results for a query can be processed efficiently. Ranking of search results, hence snippets, is determined by a complex combination of various factors unique to the underlying search engine. Therefore, no guarantee exists that all the information we need to measure semantic similarity between a given pair of words is contained in the top-ranking snippets.
This paper proposes a method that considers both page counts and lexico-syntactic patterns extracted from snippets, thereby overcoming the problems described above.
For example, let us consider the following snippet from Google for the query Jaguar AND cat.
Here, the phrase is the largest indicates a hypernymic relationship between the Jaguar and the cat. Phrases such as also known as, is a, part of, is an example of all indicate various semantic relations. Such indicative phrases have been applied to numerous tasks with good results, such as hyponym extraction [12] and fact extraction [27]. From the previous example, we form the pattern X is the largest Y, where we replace the two words Jaguar and cat by two wildcards X and Y.
Our contributions in this paper are two fold:
The remainder of the paper is organized as follows. In section 2 we discuss previous works related to semantic similarity measures. We then describe the proposed method in section 3. Section 4 compares the proposed method against previous Web-based semantic similarity measures and several baselines on a benchmark data set. In order to evaluate the ability of the proposed method in capturing semantic similarity between real-world entities, we apply it in a community mining task. Finally, we show that the proposed method is useful for disambiguating senses in ambiguous named-entities and conclude this paper.
Semantic similarity measures are important in many Web-related tasks. In query expansion [5,25,40] a user query is modified using synonymous words to improve the relevancy of the search. One method to find appropriate words to include in a query is to compare the previous user queries using semantic similarity measures. If there exist a previous query that is semantically related to the current query, then it can be suggested either to the user or internally used by the search engine to modify the original query.
Semantic similarity measures have been used in Semantic Web related applications such as automatic annotation of Web pages [7], community mining [23,19], and keyword extraction for inter-entity relation representation [26].
Semantic similarity measures are necessary for various applications in natural language processing
such as word-sense disambiguation [32], language modeling [34],
synonym extraction [16], and automatic thesauri extraction [8].
Manually compiled taxonomies such as WordNet3
and large text corpora have been used in previous works
on semantic similarity [16,31,13,17].
Regarding the Web as a live corpus has become an active research topic
recently. Simple, unsupervised models demonstrably perform better when ![]() -gram counts are
obtained from the Web rather than from a large corpus [14,15].
Resnik and Smith [33] extracted bilingual sentences from the Web
to create a parallel corpora for machine translation. Turney [38]
defined a point-wise mutual information (PMI-IR) measure using the
number of hits returned by a Web search engine to recognize synonyms.
Matsuo et. al, [20] used a similar approach to
measure the similarity between words and apply their method in a graph-based word clustering algorithm.
-gram counts are
obtained from the Web rather than from a large corpus [14,15].
Resnik and Smith [33] extracted bilingual sentences from the Web
to create a parallel corpora for machine translation. Turney [38]
defined a point-wise mutual information (PMI-IR) measure using the
number of hits returned by a Web search engine to recognize synonyms.
Matsuo et. al, [20] used a similar approach to
measure the similarity between words and apply their method in a graph-based word clustering algorithm.
Given a taxonomy of concepts, a straightforward method to calculate similarity between two words (concepts) is to find the length of the shortest path connecting the two words in the taxonomy [30]. If a word is polysemous then multiple paths might exist between the two words. In such cases, only the shortest path between any two senses of the words is considered for calculating similarity. A problem that is frequently acknowledged with this approach is that it relies on the notion that all links in the taxonomy represent a uniform distance.
Resnik [31] proposed a similarity measure using information content.
He defined the similarity between two concepts ![]() and
and ![]() in the taxonomy as the maximum of the
information content of all concepts
in the taxonomy as the maximum of the
information content of all concepts ![]() that subsume both
that subsume both ![]() and
and ![]() .
Then the similarity between two words is defined as the maximum of the similarity between any
concepts that the words belong to. He used WordNet as the taxonomy; information content is
calculated using the Brown corpus.
.
Then the similarity between two words is defined as the maximum of the similarity between any
concepts that the words belong to. He used WordNet as the taxonomy; information content is
calculated using the Brown corpus.
Li et al., [41] combined structural semantic information from a
lexical taxonomy and information content from a corpus in a nonlinear model. They proposed a
similarity measure that uses shortest path length, depth and local density in a taxonomy.
Their experiments reported a Pearson correlation coefficient of ![]() on the
Miller and Charles [24] benchmark dataset. They did not evaluate their method in terms of
similarities among named entities.
Lin [17] defined the similarity between two concepts
as the information that is in common to both concepts and the information contained in
each individual concept.
on the
Miller and Charles [24] benchmark dataset. They did not evaluate their method in terms of
similarities among named entities.
Lin [17] defined the similarity between two concepts
as the information that is in common to both concepts and the information contained in
each individual concept.
Recently, some work has been carried out on measuring semantic similarity using Web content. Matsuo et al., [19] proposed the use of Web hits for extracting communities on the Web. They measured the association between two personal names using the overlap (Simpson) coefficient, which is calculated based on the number of Web hits for each individual name and their conjunction (i.e., AND query of the two names).
Sahami et al., [36] measured semantic similarity between two
queries using snippets returned for those queries by a search engine. For each query,
they collect snippets from a search engine and represent each snippet as a TF-IDF-weighted
term vector. Each vector is ![]() normalized and the centroid of the set of vectors is
computed. Semantic similarity between two queries is then defined as the inner
product between the corresponding centroid vectors. They did not compare
their similarity measure with taxonomy-based similarity measures.
normalized and the centroid of the set of vectors is
computed. Semantic similarity between two queries is then defined as the inner
product between the corresponding centroid vectors. They did not compare
their similarity measure with taxonomy-based similarity measures.
Chen et al., [6] proposed a double-checking model using text snippets returned by
a Web search engine to compute
semantic similarity between words. For two words ![]() and
and ![]() , they collect
snippets for each word from a Web search engine. Then they count the occurrences
of word
, they collect
snippets for each word from a Web search engine. Then they count the occurrences
of word ![]() in the snippets for word
in the snippets for word ![]() and the occurrences of word
and the occurrences of word ![]() in the snippets for word
in the snippets for word ![]() .
These values are combined nonlinearly to compute the similarity between
.
These values are combined nonlinearly to compute the similarity between ![]() and
and ![]() .
This method depends heavily on the search engine's ranking algorithm.
Although two words
.
This method depends heavily on the search engine's ranking algorithm.
Although two words ![]() and
and ![]() might be very similar, there is no reason to believe that one can
find
might be very similar, there is no reason to believe that one can
find ![]() in the snippets for
in the snippets for ![]() , or vice versa. This observation is confirmed by the experimental
results in their paper which reports zero similarity scores for many pairs of words in the
Miller and Charles [24] dataset.
, or vice versa. This observation is confirmed by the experimental
results in their paper which reports zero similarity scores for many pairs of words in the
Miller and Charles [24] dataset.
We modify four popular co-occurrence measures; Jaccard, Overlap (Simpson), Dice, and PMI (Point-wise mutual information), to compute semantic similarity using page counts.
For the remainder of this paper we use the notation ![]() to denote the page counts for the query
to denote the page counts for the query ![]() in a search engine.
The WebJaccard coefficient between words (or multi-word phrases)
in a search engine.
The WebJaccard coefficient between words (or multi-word phrases)
![]() and
and ![]() ,
,
![]() , is defined as,
, is defined as,
Similarly, we define WebOverlap,
![]() , as,
, as,
We define the WebDice coefficient as a variant of the Dice coefficient.
![]() is defined as,
is defined as,
We define WebPMI as a variant form of PMI using page counts as,
Here, the relationship between Toyota and Nissan is that they are both car manufacturers. Identifying the exact set of words that convey the semantic relationship between two entities is a difficult problem which requires deeper semantic analysis. However, such an analysis is not feasible considering the numerous ill-formed sentences we need to process on the Web. In this paper, we propose a shallow pattern extraction method to capture the semantic relationship between words in text snippets.
Our pattern extraction algorithm is illustrated in Figure 3.
Given a set ![]() of synonymous word-pairs, GetSnippets function returns
a list of text snippets for the query ``A" AND ``B" for each word-pair
of synonymous word-pairs, GetSnippets function returns
a list of text snippets for the query ``A" AND ``B" for each word-pair
![]() in
in ![]() . For each snippet found, we replace the two words in the query by two wildcards.
Let us assume these wildcards to be X and Y.
For each snippet
. For each snippet found, we replace the two words in the query by two wildcards.
Let us assume these wildcards to be X and Y.
For each snippet ![]() in the set of snippets
in the set of snippets ![]() returned by GetSnippets,
function GetNgrams extract word
returned by GetSnippets,
function GetNgrams extract word ![]() -grams for
-grams for ![]() and
and ![]() .
We select
.
We select ![]() -grams which contain exactly one X and one Y.
For example, the snippet in Figure 2 yields patterns
X and Y, X and Y are, X and Y are two.
Finally, function CountFreq counts
the frequency of each pattern we extracted.
The procedure described above yields a set of patterns with
their frequencies in text snippets obtained from a search engine.
It considers the words that fall between
-grams which contain exactly one X and one Y.
For example, the snippet in Figure 2 yields patterns
X and Y, X and Y are, X and Y are two.
Finally, function CountFreq counts
the frequency of each pattern we extracted.
The procedure described above yields a set of patterns with
their frequencies in text snippets obtained from a search engine.
It considers the words that fall between ![]() and
and ![]() as well as words that precede
as well as words that precede ![]() and
succeeds
and
succeeds ![]() .
.
To leverage the pattern extraction
process, we select ![]() pairs of synonymous nouns from WordNet synsets.
For polysemous nouns we selected the synonyms for the dominant sense.
The pattern extraction algorithm described
in Figure 3 yields
pairs of synonymous nouns from WordNet synsets.
For polysemous nouns we selected the synonyms for the dominant sense.
The pattern extraction algorithm described
in Figure 3 yields ![]() unique patterns.
Of those patterns,
unique patterns.
Of those patterns, ![]() occur less than
occur less than ![]() times. It is impossible to train a classifier
with such numerous sparse patterns. We must measure the confidence of each
pattern as an indicator of synonymy. For that purpose, we employ the following procedure.
times. It is impossible to train a classifier
with such numerous sparse patterns. We must measure the confidence of each
pattern as an indicator of synonymy. For that purpose, we employ the following procedure.
First, we run the pattern extraction algorithm described in Figure 3 with a non-synonymous set of word-pairs and count the frequency of the extracted patterns. We then use a test of statistical significance to evaluate the probable applicability of a pattern as an indicator of synonymy. The fundamental idea of this analysis is that, if a pattern appears a statistically significant number of times in snippets for synonymous words than in snippets for non-synonymous words, then it is a reliable indicator of synonymy.
To create a set of non-synonymous word-pairs, we select two nouns from WordNet arbitrarily.
If the selected two nouns do not appear in any WordNet synset then we select
them as a non-synonymous word-pair. We repeat this procedure until we obtain ![]() pairs of
non-synonymous words.
pairs of
non-synonymous words.
For each extracted pattern ![]() , we create a contingency table, as shown in Table 1
using its frequency
, we create a contingency table, as shown in Table 1
using its frequency ![]() in snippets for synonymous word pairs and
in snippets for synonymous word pairs and ![]() in snippets for non-synonymous
word pairs. In Table 1,
in snippets for non-synonymous
word pairs. In Table 1,
![]() denotes the total frequency of all patterns in snippets for synonymous word pairs
(
denotes the total frequency of all patterns in snippets for synonymous word pairs
(![]() ) and
) and ![]() is the same in snippets for non-synonymous word pairs (
is the same in snippets for non-synonymous word pairs (![]() ).
).
Using the information in Table 1, we calculate the ![]() [18] value
for each pattern as,
[18] value
for each pattern as,
Before we proceed to the integration of patterns and page-counts-based similarity scores,
it is necessary to introduce some constraints to the development of semantic similarity measures.
Evidence from psychological experiments suggest that semantic similarity can be context-dependent and
even asymmetric [39,22]. Human subjects have reportedly assigned
different similarity ratings to word-pairs when the two words were presented in the reverse order.
However, experimental results investigating the effects of asymmetry reports that the average difference
in ratings for a word pair is less than ![]() percent [22]. In this work, we assume semantic similarity to be
symmetric. This is in line with previous work on semantic similarity described in section 2.
Under this assumption, we can interchange the query word markers X and
Y in the extracted patterns.
percent [22]. In this work, we assume semantic similarity to be
symmetric. This is in line with previous work on semantic similarity described in section 2.
Under this assumption, we can interchange the query word markers X and
Y in the extracted patterns.
In section 3.2 we defined four similarity scores using page counts. Section 3.3 described a lexico-syntactic pattern extraction algorithm and ranked the patterns according to their ability to express synonymy. In this section we describe leverage of a robust semantic similarity measure through integration of all the similarity scores and patterns described in previous sections.
For each pair of words ![]() , we create a feature vector
, we create a feature vector ![]() as shown in Figure 4.
First, we query Google for ``
as shown in Figure 4.
First, we query Google for ``![]() " AND ``
" AND ``![]() " and collect snippets.
Then we replace the query words
" and collect snippets.
Then we replace the query words ![]() and
and ![]() with two wildcards
with two wildcards ![]() and
and ![]() , respectively in each
snippet. Function GetNgrams extracts
, respectively in each
snippet. Function GetNgrams extracts ![]() -grams for
-grams for ![]() and
and ![]() from the snippets.
We select
from the snippets.
We select ![]() -grams having exactly one
-grams having exactly one ![]() and one
and one ![]() as we did in the pattern extraction algorithm
in Figure 3. Let us assume the set of patterns selected based on their
as we did in the pattern extraction algorithm
in Figure 3. Let us assume the set of patterns selected based on their ![]() values in section 3.3 to be
values in section 3.3 to be ![]() . Then, the function SelectPatterns
selects the
. Then, the function SelectPatterns
selects the ![]() -grams from
-grams from ![]() which appear in
which appear in ![]() . In
. In
![]() , we normalize the
count of each pattern by diving it from the total number of counts of the observed patterns.
This function returns a vector of patterns where each element is the normalized frequency
of the corresponding pattern in the snippets for the query
, we normalize the
count of each pattern by diving it from the total number of counts of the observed patterns.
This function returns a vector of patterns where each element is the normalized frequency
of the corresponding pattern in the snippets for the query ![]() . We append similarity scores
calculated using page counts in section 3.2 to create the final feature vector
. We append similarity scores
calculated using page counts in section 3.2 to create the final feature vector ![]() for the word-pair
for the word-pair ![]() . This procedure yields a
. This procedure yields a ![]() dimensional (
dimensional (![]() page-counts based similarity scores and
page-counts based similarity scores and ![]() lexico-syntactic patterns) feature vector
lexico-syntactic patterns) feature vector ![]() . We form such feature vectors for all synonymous word-pairs (positive training examples) as well as for non-synonymous word-pairs (negative training examples). We then train a two-class support vector machine with the labelled feature vectors.
. We form such feature vectors for all synonymous word-pairs (positive training examples) as well as for non-synonymous word-pairs (negative training examples). We then train a two-class support vector machine with the labelled feature vectors.
Once we have trained an SVM using synonymous and non-synonymous word pairs, we can use it
to compute the semantic similarity between two given words. Following the same method we used to generate feature vectors for training, we create a feature vector ![]() for the given pair of words
for the given pair of words
![]() , between which we need to measure the semantic similarity.
We define the semantic similarity
, between which we need to measure the semantic similarity.
We define the semantic similarity
![]() between
between
![]() and
and ![]() as the posterior probability
as the posterior probability
![]() that feature vector
that feature vector ![]() belongs to
belongs to
the synonymous-words (positive) class.
Being a large-margin classifier, the output of an SVM is the distance from the decision hyper-plane. However, this is not a calibrated posterior probability. We use sigmoid functions to convert this uncalibrated distance into a calibrated posterior probability (see [29] for a detailed discussion on this topic).
We conduct two sets of experiments to evaluate the proposed semantic similarity measure. First we compare the similarity scores produced by the proposed measure against Miller-Charles benchmark dataset. We analyze the behavior of the proposed measure with the number of patterns used as features, the number of snippets used to extract the patterns, and the size of the training dataset. Secondly, we apply the proposed measure in two real-world applications: community mining and entity disambiguation.
| feature | SVM weight | |
| WebDice | N/A | |
| X/Y | ||
| X, Y : | ||
| X or Y | ||
| X Y for | ||
| X . the Y | ||
| with X ( Y | ||
| X=Y | ||
| X and Y are | ||
| X of Y |
We trained a linear kernel SVM with top ![]() pattern features (ranked according to
their
pattern features (ranked according to
their ![]() values) and calculated the correlation coefficient against the Miller-Charles
benchmark dataset. Results of the experiment are shown in Figure 5.
In Figure 5 a steep improvement of correlation with the number
of top-ranking patterns is appearent; it reaches a maximum at
values) and calculated the correlation coefficient against the Miller-Charles
benchmark dataset. Results of the experiment are shown in Figure 5.
In Figure 5 a steep improvement of correlation with the number
of top-ranking patterns is appearent; it reaches a maximum at ![]() features. With more than
features. With more than ![]() patterns
correlation drops below this maximum. Considering that the patterns are ranked
according to their ability to express semantic similarity and the majority of patterns are sparse,
we selected only the top ranking
patterns
correlation drops below this maximum. Considering that the patterns are ranked
according to their ability to express semantic similarity and the majority of patterns are sparse,
we selected only the top ranking ![]() patterns for the remaining experiments.
patterns for the remaining experiments.
Features with the highest linear kernel weights are
shown in Table 2 alongside their ![]() values. The weight of a feature in the linear
kernel can be considered as a rough estimate of the influence it imparts on the final
SVM output. WebDice has the highest kernel weight followed by a series of
pattern-based features. WebOverlap (rank=
values. The weight of a feature in the linear
kernel can be considered as a rough estimate of the influence it imparts on the final
SVM output. WebDice has the highest kernel weight followed by a series of
pattern-based features. WebOverlap (rank=![]() , weight=
, weight=![]() ),
WebJaccard (rank=
),
WebJaccard (rank=![]() , weight=
, weight=![]() ) and WebPMI (rank=
) and WebPMI (rank=![]() , weight=
, weight=![]() )
are not shown in Table 2 because of space limitations. It is noteworthy that
the pattern features in Table 2 agree with intuition. Lexical patterns (e.g.,
X or Y, X and Y are, X of Y) as well as syntax patterns (e.g., bracketing, comma usage)
are extracted by our method.
)
are not shown in Table 2 because of space limitations. It is noteworthy that
the pattern features in Table 2 agree with intuition. Lexical patterns (e.g.,
X or Y, X and Y are, X of Y) as well as syntax patterns (e.g., bracketing, comma usage)
are extracted by our method.
| Kernel Type | Correlation |
| Linear | |
| Polynomial degree= |
|
| Polynomial degree= |
|
| RBF | |
| Sigmoid |
We experimented with different kernel types as shown in Table 3.
Best performance is achieved with the linear kernel. When higher degree kernels such
as quadratic (Polynomial degree=![]() ) and cubic (Polynomial degree=
) and cubic (Polynomial degree=![]() ) are used, correlation with
the human ratings decreases rapidly. Second best is the Radial Basis Functions (RBFs),
which reports a correlation coefficient of
) are used, correlation with
the human ratings decreases rapidly. Second best is the Radial Basis Functions (RBFs),
which reports a correlation coefficient of ![]() . For the rest of the experiments in this paper
we use the linear kernel.
. For the rest of the experiments in this paper
we use the linear kernel.
| Word Pair | Miller- | Web | Web | Web | Web | Sahami [36] | CODC [6] | Proposed |
| Charles' | Jaccard | Dice | Overlap | PMI | SemSim | |||
| cord-smile | ||||||||
| rooster-voyage | ||||||||
| noon-string | ||||||||
| glass-magician | ||||||||
| monk-slave | ||||||||
| coast-forest | ||||||||
| monk-oracle | ||||||||
| lad-wizard | ||||||||
| forest-graveyard | ||||||||
| food-rooster | ||||||||
| coast-hill | ||||||||
| car-journey | ||||||||
| crane-implement | ||||||||
| brother-lad | ||||||||
| bird-crane | ||||||||
| bird-cock | ||||||||
| food-fruit | ||||||||
| brother-monk | ||||||||
| asylum-madhouse | ||||||||
| furnace-stove | ||||||||
| magician-wizard | ||||||||
| journey-voyage | ||||||||
| coast-shore | ||||||||
| implement-tool | ||||||||
| boy-lad | ||||||||
| automobile-car | ||||||||
| midday-noon | ||||||||
| gem-jewel | ||||||||
| Correlation |
|---|
We score the word pairs in Miller-Charles' dataset using the page-count-based similarity scores
defined in section 3.2, Web-based semantic similarity measures proposed in previous
work (Sahami [36], Chen [6]) and the proposed method (SemSim).
Results are shown in Table 4.
All figures, except those for the Miller-Charles ratings,
are normalized into values in ![]() range for ease of comparison.
Pearson's correlation coefficient is invariant against a linear transformation.
Proposed method earns the highest correlation of
range for ease of comparison.
Pearson's correlation coefficient is invariant against a linear transformation.
Proposed method earns the highest correlation of ![]() in our experiments.
It shows the highest similarity score for the word-pair magician and wizard.
Lowest similarity is reported for cord and smile7.
Our reimplementation of Co-occurrence Double Checking (CODC) measure
[6] indicates the second-best correlation of
in our experiments.
It shows the highest similarity score for the word-pair magician and wizard.
Lowest similarity is reported for cord and smile7.
Our reimplementation of Co-occurrence Double Checking (CODC) measure
[6] indicates the second-best correlation of ![]() .
The CODC measure is defined as,
.
The CODC measure is defined as,
Similarity measure proposed by Sahami et al. [36] is placed third, reflecting a correlation of ![]() .
This method use only those snippets when calculating semantic similarity.
Among the four page-counts-based measures, WebPMI garners the highest correlation (
.
This method use only those snippets when calculating semantic similarity.
Among the four page-counts-based measures, WebPMI garners the highest correlation (![]() ).
Overall, the results in Table 4 suggest that similarity measures based on snippets are more accurate
than the ones based on page counts in capturing semantic similarity.
).
Overall, the results in Table 4 suggest that similarity measures based on snippets are more accurate
than the ones based on page counts in capturing semantic similarity.
| Method | Correlation |
| Human replication | |
| Resnik (1995) | |
| Lin (1998) | |
| Li et al. (2003) | |
| Edge-counting | |
| Information content | |
| Jiang & Conrath (1998) | |
| Proposed |
Table 5 presents a comparison of the proposed method to the WordNet-based methods.
The proposed method outperforms simple WordNet-based approaches such as Edge-counting and
Information Content measures. It is comparable with Lin (1998) [17]
Jiang & Conrath (1998) [13] and Li (2003) [41] methods.
Unlike the WordNet based methods, proposed
method requires no a hierarchical taxonomy of concepts or sense-tagged definitions of words.
Therefore, in principle the proposed method could be used to calculate semantic similarity
between named entities, etc, which are not listed in WordNet or other manually compiled
thesauri. However, considering the high correlation between human subjects (![]() ),
there is still room for improvement.
),
there is still room for improvement.
We computed the correlation with the Miller-Charles ratings for different numbers of snippets to investigate the effect of the number of snippets used to extract patterns upon the semantic similarity measure. The experimental results are presented in Figure 6. From Figure 6 it is appearent that overall the correlation coefficient improves with the number of snippets used for extracting patterns. The probability of finding better patterns increases with the number of processed snippets. That fact enables us to represent each pair of words with a rich feature vector, resulting in better performance.
We used synonymous word pairs extracted from WordNet synsets as positive training examples and
automatically generated non-synonymous word pairs as negative training examples to train
a two-class support vector machine in section 3.4. To determine the optimum combination
of positive and negative training examples, we trained a linear kernel SVM with different combinations of
positive and negative training examples and evaluated accuracy against the human ratings in
the Miller-Charles benchmark dataset. Experimental results are summarized in Figure 7.
Maximum correlation coefficient of ![]() is achieved with
is achieved with ![]() positive training examples and
positive training examples and
![]() negative training examples.
Moreover, Figure 7 reveals that correlation does not improve beyond
negative training examples.
Moreover, Figure 7 reveals that correlation does not improve beyond ![]() positive
and negative training examples. Therefore, we can conclude that
positive
and negative training examples. Therefore, we can conclude that ![]() examples are sufficient to leverage
the proposed semantic similarity measure.
examples are sufficient to leverage
the proposed semantic similarity measure.
[width=6cm, height=5cm]train.eps
|
In order to evaluate the performance of the proposed measure in capturing
the semantic similarity between named-entities, we set up a community mining task.
We select ![]() personal names from
personal names from ![]() communities: tennis players, golfers,
actors, politicians and scientists
, (
communities: tennis players, golfers,
actors, politicians and scientists
, (![]() names from each community) from the open directory project (DMOZ)8.
For each pair of names in our data set, we measure their similarity using
the proposed method and baselines. We use group-average agglomerative
hierarchical clustering (GAAC) to cluster the names in our dataset into five clusters.
names from each community) from the open directory project (DMOZ)8.
For each pair of names in our data set, we measure their similarity using
the proposed method and baselines. We use group-average agglomerative
hierarchical clustering (GAAC) to cluster the names in our dataset into five clusters.
Initially, each name is assigned to a separate cluster. In subsequent iterations, group
average agglomerative clustering process, merges the two clusters with highest correlation.
Correlation,
![]() between two clusters
between two clusters ![]() and
and ![]() is defined as the following,
is defined as the following,
Here, ![]() is the merger of the two clusters
is the merger of the two clusters ![]() and
and ![]() .
. ![]() denotes the number of
elements (persons) in
denotes the number of
elements (persons) in ![]() and
and
![]() is the semantic similarity between two
persons
is the semantic similarity between two
persons ![]() and
and ![]() in
in ![]() . We terminate GAAC process when exactly
five clusters are formed. We adopt this clustering method with different semantic similarity measures
. We terminate GAAC process when exactly
five clusters are formed. We adopt this clustering method with different semantic similarity measures
![]() to compare their accuracy in clustering people who belong to the same community.
to compare their accuracy in clustering people who belong to the same community.
We employed the B-CUBED metric [1] to evaluate the clustering results.
The B-CUBED evaluation metric was originally proposed for evaluating cross-document co-reference chains.
We compute precision, recall and ![]() -score for each name in the data set and average the results
over the dataset. For each person
-score for each name in the data set and average the results
over the dataset. For each person ![]() in our data set, let us denote the cluster that
in our data set, let us denote the cluster that
![]() belongs to by
belongs to by ![]() . Moreover, we use
. Moreover, we use ![]() to denote the affiliation of person
to denote the affiliation of person ![]() ,
e.g.,
,
e.g., ![]() ``Tiger Woods"
``Tiger Woods"![]() ``Tennis Player". Then we calculate precision and recall for person
``Tennis Player". Then we calculate precision and recall for person ![]() as,
as,
Since, we selected ![]() people from each of the five categories, the denominator in
Formula 10 is
people from each of the five categories, the denominator in
Formula 10 is ![]() for all the names
for all the names ![]() .
.
Then, the ![]() -score of person
-score of person ![]() is defined as,
is defined as,
Overall precision, recall and ![]() -score are computed by taking the averaged sum over all
the names in the dataset.
-score are computed by taking the averaged sum over all
the names in the dataset.
 |
(12) |
 |
(13) |
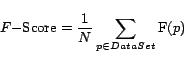 |
(14) |
Here, ![]() is the set of
is the set of ![]() names selected from the open directory project.
Therefore,
names selected from the open directory project.
Therefore, ![]() in our evaluations.
in our evaluations.
Experimental results are shown in Table 6.
The proposed method shows the highest entity clustering accuracy in Table 6
with a statistically significant (![]() Tukey HSD) F score of
Tukey HSD) F score of ![]() .
Sahami et al. [36]'s snippet-based similarity measure,
WebJaccard, WebDice and WebOverlap measures yield similar clustering accuracies.
.
Sahami et al. [36]'s snippet-based similarity measure,
WebJaccard, WebDice and WebOverlap measures yield similar clustering accuracies.
| Method | Precision | Recall | |
| WebJaccard | |||
| WebOverlap | |||
| WebDice | |||
| WebPMI | |||
| Sahami [36] | |||
| Chen [6] | |||
| Proposed |
Disambiguating named entities is important in various applications such as information retrieval [9], social network extraction [19,3,4], Word Sense Disambiguation (WSD) [21], citation matching [11] and cross-document co-reference resolution [28,10].
For example, Jaguar is a cat, a car brand and also an operating system for computers. A user who searches for Jaguar on the Web, may be interested in either one of these different senses of Jaguar. However, only the first sense (Jaguar as a cat) is listed in WordNet. Considering the number of new senses constantly being associated to the existing words on the Web, it is costly, if not impossible to maintain sense tagged dictionaries to cover all senses.
Contextual Hypothesis for Sense [37] states that the context in which
a word appears can be used to determine its sense. For example, a Web page discussing Jaguar as a car,
is likely to talk about other types of cars, parts of cars etc. Whereas, a Web page on Jaguar the cat,
is likely to contain information about other types of cats and animals. In this section, we utilize the
clustering algorithm described in section 4.7 to cluster the top ![]() snippets returned by
Google for two ambiguous entities Jaguar and Java. We represent each snippet as a
bag-of-words and calculate the similarity
snippets returned by
Google for two ambiguous entities Jaguar and Java. We represent each snippet as a
bag-of-words and calculate the similarity
![]() between two snippets
between two snippets ![]() ,
,![]() as follows,
as follows,
In Formula 15 ![]() denotes the number of words in snippet
denotes the number of words in snippet ![]() .
We used different semantic similarity measures for
.
We used different semantic similarity measures for ![]() in Formula 15
and employed the group average agglomerative clustering explained in section 4.7.
We manually analyzed the snippets for queries Java (3 senses: programming language,
Island, coffee) and Jaguar (3 senses: cat, car, operating system) and
computed precision, recall and F-score for the clusters created by the algorithm.
in Formula 15
and employed the group average agglomerative clustering explained in section 4.7.
We manually analyzed the snippets for queries Java (3 senses: programming language,
Island, coffee) and Jaguar (3 senses: cat, car, operating system) and
computed precision, recall and F-score for the clusters created by the algorithm.
Our experimental results are summarized in Table 7. Proposed method reports the best results among all the baselines compared in Table 7. However, the experiment needs to be carried out on a much larger data set of ambiguous entities in order to obtain any statistical guarantees.
| Jaguar | Java | |||||
| Method | Precision | Recall | F | Precision | Recall | F |
| WebJaccard | ||||||
| WebOverlap | ||||||
| WebDice | ||||||
| WebPMI | ||||||
| Sahami [36] | ||||||
| CODC [6] | ||||||
| Proposed | ||||||
In this paper, we proposed a measure that uses both page counts and snippets to
robustly calculate semantic similarity between two given words or named entities.
The method consists of four page-count-based similarity scores and automatically extracted
lexico-syntactic patterns. We integrated page-counts-based similarity scores with
lexico syntactic patterns using support vector machines. Training data were
automatically generated using WordNet synsets. Proposed method outperformed all the baselines
including previously proposed Web-based semantic similarity measures on a benchmark dataset.
A high correlation (correlation coefficient of ![]() )
with human ratings was found for semantic similarity on this benchmark dataset.
Only
)
with human ratings was found for semantic similarity on this benchmark dataset.
Only ![]() positive examples and
positive examples and ![]() negative examples are necessary to leverage the
proposed method, which is efficient and scalable because it
only processes the snippets (no downloading of
Web pages is necessary) for the top ranking results by Google.
A contrasting feature of our method compared to the WordNet based semantic similarity measures is
that our method requires no taxonomies, such as WordNet, for calculation of similarity. Therefore, the proposed
method can be applied in many tasks where such taxonomies do not exist or are not up-to-date.
We employed the proposed method in community mining and entity disambiguation experiments.
Results of our experiments indicate that the proposed method can robustly capture semantic similarity
between named entities.
In future research, we intend to apply the proposed semantic similarity measure in
automatic synonym extraction, query suggestion and name alias recognition.
negative examples are necessary to leverage the
proposed method, which is efficient and scalable because it
only processes the snippets (no downloading of
Web pages is necessary) for the top ranking results by Google.
A contrasting feature of our method compared to the WordNet based semantic similarity measures is
that our method requires no taxonomies, such as WordNet, for calculation of similarity. Therefore, the proposed
method can be applied in many tasks where such taxonomies do not exist or are not up-to-date.
We employed the proposed method in community mining and entity disambiguation experiments.
Results of our experiments indicate that the proposed method can robustly capture semantic similarity
between named entities.
In future research, we intend to apply the proposed semantic similarity measure in
automatic synonym extraction, query suggestion and name alias recognition.
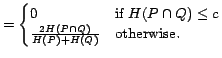
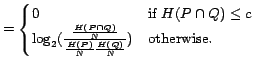
![\begin{figure}
\begin{pseudocode}[ovalbox]{ExtractPatterns}{S}
\small\COMMENT{...
...
\RETURN{Pats}
\end{pseudocode}
\vspace{-8mm}
\vspace{-3mm}
\end{figure}](www_camera-img38.png)
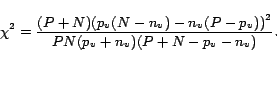
![\begin{figure}
\begin{pseudocode}[ovalbox]{GetFeatureVector}{A,B}
\small\COMME...
...\
\RETURN{F}
\end{pseudocode}
\vspace{-8mm}
\vspace{-3mm}
\end{figure}](www_camera-img62.png)
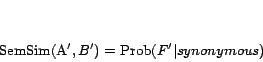
![$\displaystyle =\begin{cases}
0 & \text{if $f(P @ Q)=0$} \cr
e^{\log \left[ {\fr...
...} \times \frac{f(Q @ P)}{H(Q)}} \right] ^\alpha}& \text{otherwise}.
\end{cases}$](www_camera-img302.png)